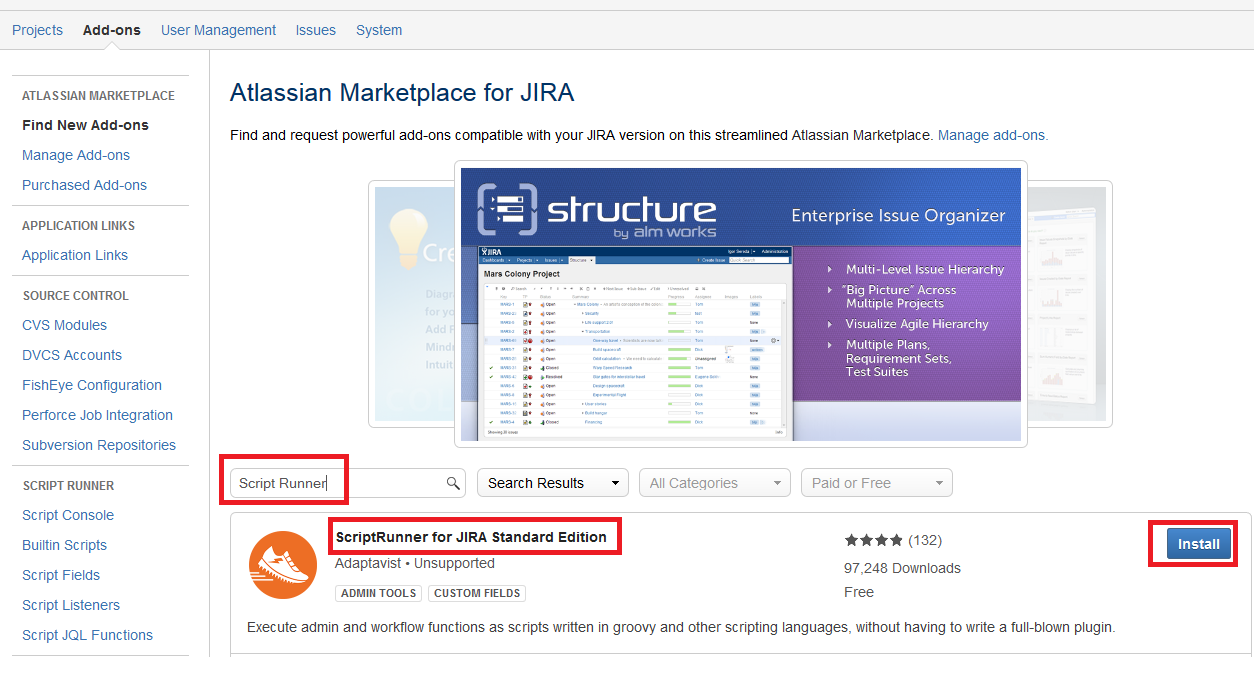
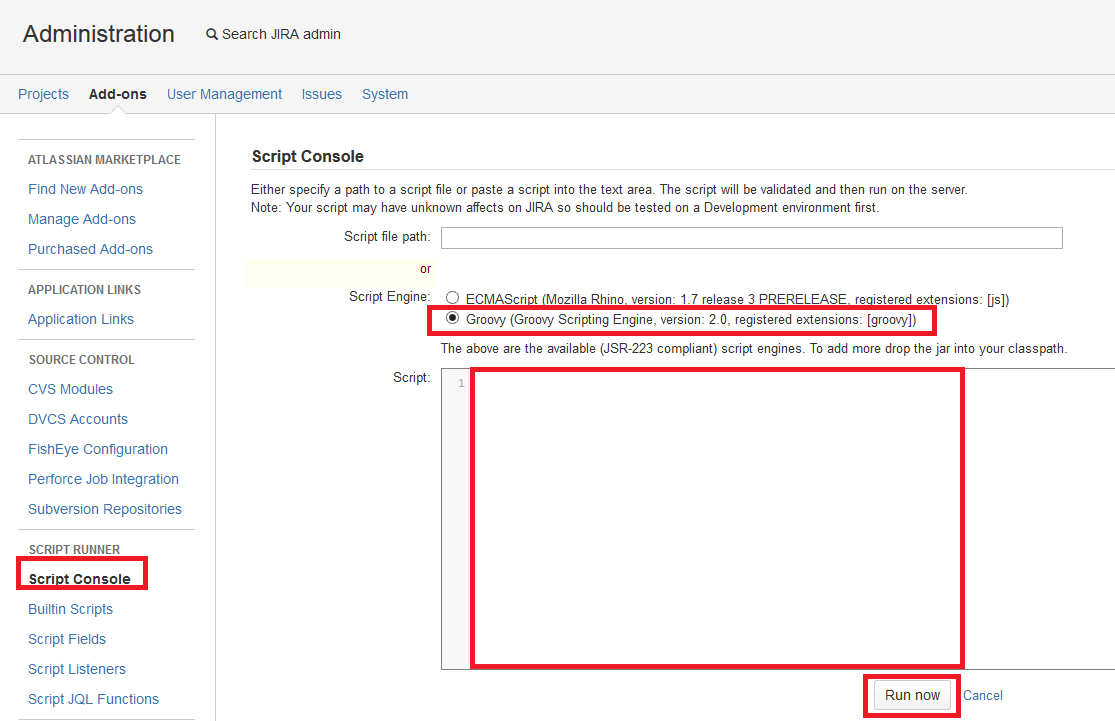
import com.atlassian.jira.component.ComponentAccessor
import com.atlassian.jira.issue.IssueManager
import com.atlassian.jira.issue.MutableIssue
import com.atlassian.jira.issue.comments.Comment
import com.atlassian.jira.issue.comments.CommentManager
String issueKey = 'FOOBAR-10'
IssueManager issueManager = ComponentAccessor.issueManager
CommentManager commentManager = ComponentAccessor.commentManager
MutableIssue issue = issueManager.getIssueObject(issueKey)
List<Comment> comments = commentManager.getComments(issue)
comments.each {comment ->
if (comment.body.contains('http://www.olympiacycleomaha.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.tecnotelevision.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.oliver-sinz.de')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://rentamom.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.sniderscyclery.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://modernhomeauction.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://souleye.se')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://parametricmodel.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://graceibc.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.armanios.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.malaysiaflora.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.salomontrailtour.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://efjakarta.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.antabusebuy.net')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://akss.net')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://villave.no')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.diabeticcareassociates.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://buyventolin.info')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.heycupcakebakery.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.commonstudio.pl')) {
commentManager.delete(comment)
}
else if (comment.body.contains('https://www.ijmuk.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.drijendesigns.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://lynnefreeman.net')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.intwinedbows.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.jugarcasinoonline.co')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://paxil.info')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.whiteslaw.com.au')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.irishmaritimelaw.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.davehebb.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.marcovernaschi.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.cleanmedeurope.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://buffalovisiongames.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.elsiemagazine.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://fundraisingboxes.ie')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.dreambulgarianproperty.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.bigredtank.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.piritubafuscaclub.com.br')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.overheardinpittsburgh.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.ymirbc.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.iobm.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.maxicrop.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.trumbly.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.winsorcreative.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.borytucholskie.las.pl')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.thecanoeman.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.allhotelsnepal.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.fivepointsnacks.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.intrige.nl')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.graphicdetail.co.nz')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.smhv.nl')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.fabulousfordsforever.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.waynehastings.net')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.fuzzyfocus.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.gagaku.net')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.samhardenburgh.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.indiamanufacturingshow.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://coactiv.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.jmktrust.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.bristolcyclingcampaign.org.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.glasfryn.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.mediagang.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.rehabilitacja-amed.pl')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.aslan.ie')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.thinkcms.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://modtriangle.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.ctahperd.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.ethical-pets.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('https://www.manxfarmcottages.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.iamcreative.org.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.gesitra-seimc.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.stypendia-bialystok.pl')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.iniomusic.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.flyeauclaire.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://ferso.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://teawithanarchitect.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.ccborobia.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://teawithanarchitect.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.adrenalicia.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://midwestdrafting.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://mobilewebghana.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.rpptl.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://madebywe.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.pizzaamorewoodfire.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.7pennies.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://globalenglish.co.il')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.wetyourpantsfilmfest.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.lynnlyonsnh.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.cellogel.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://amazinglist.net')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.townofcaroline.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://arsitektur.upi.edu')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://buycytotec.storemeds.net')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://donterra.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://escenadigital.net')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://fipac.ca')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://greenhomeoregon.net')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://jubileetroupe.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://playground.danielvasquez.cl')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.alternative-regionalisms.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.armandobayolo.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.aufildujeu.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.bergstatt.at')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.civilprocedurereview.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.consumosolidario.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.fundacionmasaveu.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.governmentbudgetofficersurvey.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.greatnoiseensemble.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.greenmountaincreamery.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.japansociety-ni.org.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.larneda.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.medicallab.org.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.nickscullion.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.piscesttjobs.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.pujcovnachmela.cz')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.queenofsmalladventures.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.texascremationservices.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.tomitadesigns.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.oakleymentalhealth.co.nz')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.ucheducationcentre.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.studio.langford.co.il')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://lettertoadisciple.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.myriam-gourfink.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.internet-casinos.es')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.lynnesdesigns.net')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.athenaadvisors.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://landofthewaterfalls.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://anestasiavodka.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('https://ummgc.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://uberdorkdesigns.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.2seotons.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.azurrestaurant.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.fitxpress.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.phoebe-berlin.de')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://michigansportscenter.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.uberdorkcafe.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://meamaximaculpa.ie')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://buycytotec.net')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.janedakool.ee')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.buynaltrexone.info')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.highlineathleticclub.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.criminallawonline.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.crickethillwinery.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.khsauter.de')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://nation-branding.info')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.museeaustralien.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.empex.pl')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.hagada.pl')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://beyond-digital.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.chriskeam.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.johnbarry.org.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.thinkgenealogy.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.beyond-digital.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.adsprecision.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.crisishq.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://tulsacf.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://bowhunterwebsites.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.currentconservation.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.biodiesel.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://dematosryan.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.facturaok.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.sleepinischeatin.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.hysens.eu')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.carriagecrossing.ca')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://tedxbrum.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.thesmetimes.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://cotswoldgold.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.karhuski.fi')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.mercachem.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.choosecornish.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.twindots.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://clueb.it')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.icbonline.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://lovl.ee')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.adityamooley.net')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.petersencreative.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://berkshiresailing.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.feritbulut.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.eduxconsult.com.br')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.weeboos.nl')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://ailleriverhosteldoolin.ie')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://ninemeds.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://annbrandeis.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://feops.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://thefratellis.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://theacceleratornetwork.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.hurricanemedia.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://cymhin.offordcentre.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.lullinferrari.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.medasil.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.dinebirmingham.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.amblesideac.org.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.champoegnursery.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.emilyballatseawhite.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('https://diverseabilities.org.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.circle-one.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.tomandsteve.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.varosvillage.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://idealcases.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://fit2rundirect.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.dr-pap.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.fasrm.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.bvpanthers.com.au')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.meridianwest.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://bucintoro.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://theplanets.org')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.racingtoregister.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.cygnetmarquees.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://aidenbyrne.co.uk')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.el-tom.de')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.pitturaedintorni.it')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://teamkbs.com')) {
commentManager.delete(comment)
}
else if (comment.body.contains('http://www.restorantfloga.com')) {
commentManager.delete(comment)
}
}